Modernizing Machine Learning Workloads: How OEMs can Scale Spark ML with Azure HDInsight
Introduction: The shift toward scalable, intelligent OEM operations
Today’s equipment manufacturers are under growing pressure to deliver more than just reliable hardware. Customers now expect intelligent, self-optimizing systems that optimize performance, reduce downtime, and provide real-time insights. To meet these demands, equipment manufacturers are rapidly adopting AI and Machine Learning (ML) capabilities. But building and scaling these solutions - especially when they originate from on-premise environments - remains a significant challenge.
For industrial OEMs looking to modernize their analytics and AI infrastructure, cloud-native solutions like Apache Spark ML on Azure HDInsight offer a clear path forward. This article explores how a leading manufacturer successfully transitioned its ML workloads to the cloud - and how others can do the same.
Problem statement: The challenge of scaling ML in legacy environments
Many OEMs began their Machine Learning journey by developing analytics solutions on local servers, experimenting with tools like Apache Spark or Amazon SageMaker, to build models that predicted equipment failure or optimized asset utilization. However, as these models matured, the limitations of on-premise infrastructure became clear:
- High maintenance overhead from managing Spark clusters manually.
- Poor scalability when ingesting and processing high-volume industrial data.
- Limited accessibility for distributed teams and data consumers.
These constraints hindered time-to-insight and prevented OEMs from operationalizing their Machine Learning solutions at scale - precisely when their customers began demanding more intelligent products.
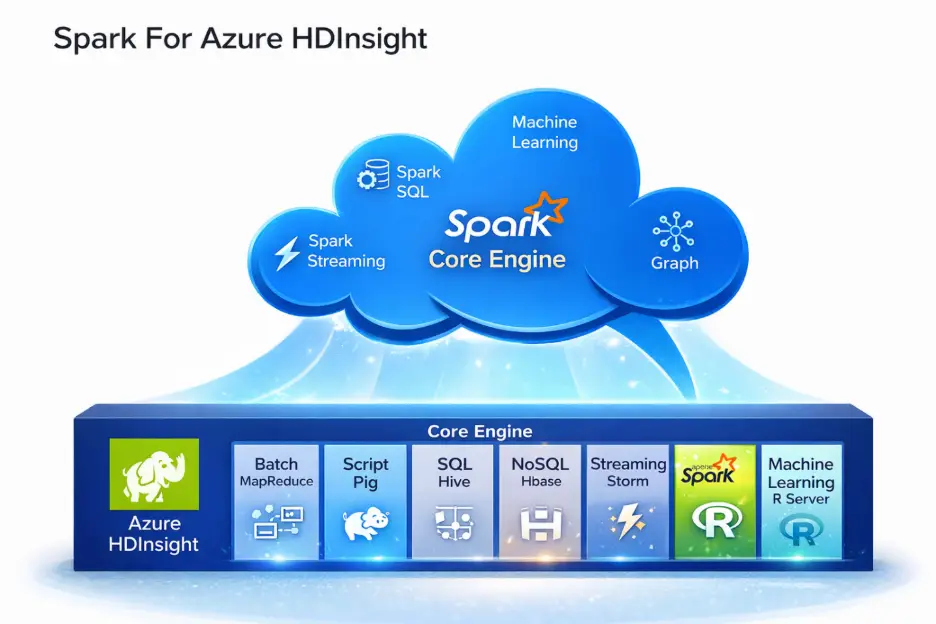
Solution: Scaling ML with Spark on Azure HDInsight
To address these challenges, a global manufacturing client partnered with Saviant that offers machine learning consulting services to migrate and modernize their ML infrastructure on Microsoft Azure. Our approach leveraged Azure HDInsight, a fully managed cloud service that supports open-source frameworks like Apache Spark, to enable scalable, maintainable, and production-grade ML capabilities.
Key implementation steps:
- Provisioned a Spark cluster using Azure HDInsight, eliminating infrastructure overhead and enabling dynamic scaling.
- Developed Jupyter PySpark notebooks to run interactive Spark SQL queries, transform data, and visualize outputs—all within the cluster environment.
- Connected directly to Azure Blob Storage (WASB) for seamless data ingestion from distributed assets.
- Migrated existing models to Spark MLlib, enabling regression and classification tasks for severity and certainty prediction.
- Operationalized the ML pipeline, with outputs returning actionable predictions in real time.
This end-to-end migration enabled the client to run complex ML experiments - such as linear regression models for predictive maintenance at cloud scale, reducing latency and improving collaboration across data science teams.
Case Study: Empowering Predictive Analytics in Manufacturing
The manufacturing company had been using Spark-based ML algorithms locally to assess operational risk in real time. By migrating to Azure, they achieved:
- Improved prediction accuracy, due to faster iteration cycles and better data availability.
- 75% reduction in model training time, thanks to elastic computing resources.
- Enhanced maintainability, with Spark clusters managed via the Azure portal and integrated seamlessly into DevOps pipelines.
As a result, the client was able to deploy ML models in production within weeks, empowering plant operators with real-time insights and laying the foundation for future smart equipment monetization.
Strategic benefits for smart machine and equipment manufacturers
Spark ML on Azure is more than a technical upgrade - it’s a strategic enabler for OEMs that want to:
- Reduce operational costs: Avoid capital expenses tied to maintaining on-premise clusters.
- Drive premium software adoption: Offer ML-driven features (e.g., automated diagnostics, predictive analytics) as part of a premium software tier.
- Accelerate AIoT deployment: Quickly go from proof-of-concept to production with scalable infrastructure.
These capabilities are especially vital for smart machine manufacturers exploring freemium-to-premium transitions, where advanced analytics features can drive new revenue streams and enhance customer loyalty.
Conclusion: Building for scale, competing with intelligence
For smart machine and equipment manufacturers, modernizing ML infrastructure is no longer a future initiative - it’s a present-day imperative. Migrating Spark ML workloads to Azure HDInsight enables scalable, efficient, and production-ready analytics that unlock new value from smart equipment.
By moving beyond legacy systems, OEMs can deliver real-time insights, reduce operational overhead, and lay the groundwork for monetizing intelligent features. In today’s competitive landscape, those who modernize now will define the next generation of industrial innovation.